
今天我们来介绍一下下一位朋友,堆排序!
堆排序是一种树形选择排序方法,它的特点是,在排序过程中,将 Data[0..n-1] 看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素。
堆排序的排序过程中每次挑选最大元素归位,如图所示。挑选最大元素的方法是将数组中存储的数据看成是一棵完全二叉树,利用完全二叉树中双亲节点和孩子节点之间的内在关系来选择关键字最大的元素。具体的做法是:把待排序的表的关键字存放在数组Data[0..n-1] 之中,将 Data 看做一棵二叉树,每个节点表示一个元素,源表的第一个元素Data[0] 作为二叉树的根,以下各元素 Data[1..n-1] 依次逐层从左到右顺序排列,构成一棵完全二叉树,节点 Data[i] 的左孩子是 Data[2i+1],右孩子是 Data[2i+2],双亲是 Data[(i+1)/2-1]。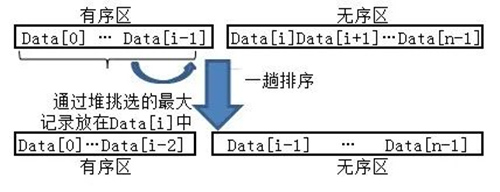
▲ 堆排序的一趟排序过程
※说明:堆排序每趟产生的有序区一定是全局有序区,也就是说每趟产生的有序区中所有元素都归位了。
设待排序的表有 10 个元素,其关键字为 {6,8,7,9,0,1,3,2,4,5}。以下为堆排序的排序过程:
其初始状态如下图(a)所示,通过第一个for循环调用sift() 产生的初始堆如下图(b)所示,这时Data中关键字序列为{9,8,7,6,5,1,3,2,4,0}。
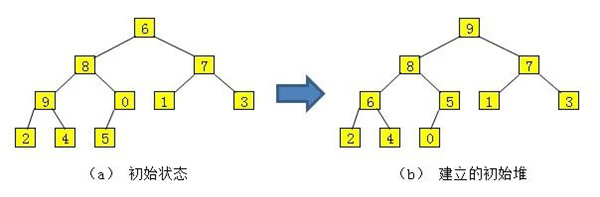
▲ 建立初始堆
堆排序的排序过程如下图所示,每输出一个元素,就对堆进行一次筛选调整。
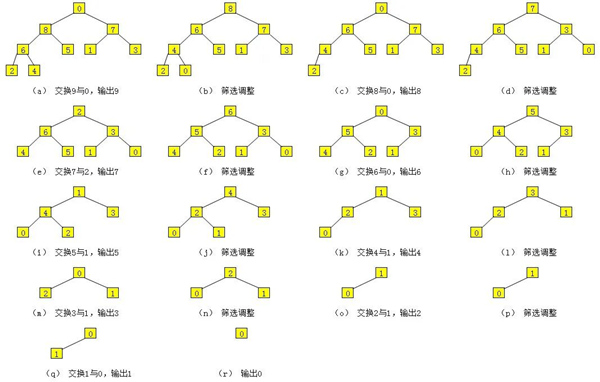
▲ 堆排序过程

时间复杂度:O(nlog2n);
空间复杂度:O(1);
稳定性:不稳定;
复杂性:较复杂。
今天就分享到这里啦~





关注东软睿道公众号了解更多IT行业资讯

添加东小萌微信
获取更多IT学习资源






